텍스트 형태의 pdf면 문자 추출이 조금 용이하나, 이미지 형태의 pdf에서 문자 추출을 위해서는
OCR(광학문자인식, Optimal Character Recognition)을 활용해야 합니다.
OCR을 위한 패키지로는 pytesseract, EasyOCR, paddleOCR, Naver CLOVA OCR 등 다양하게 많습니다만..
python 개발 환경에서 무료로 접근하기 가장 편한건 pytesseract입니다.
일단 큰 틀의 절차는 3가지로 볼 수 있습니다.
① pdf 열기 및 이미지 추출 ② OCR을 위한 이미지 처리 ③ OCR 및 보정
먼저 각각의 절차를 위한 패키지 설치를 해야겠죠?
1) 패키지 설치 - pdf를 읽기 위한 pymupdf 설치

1) 패키지 설치 - 이미지 처리를 위한 opencv 설치

1) 패키지 설치 - pytesseract 설치 (윈도우용 프로그램 및 패키지)
https://github.com/UB-Mannheim/tesseract/wiki
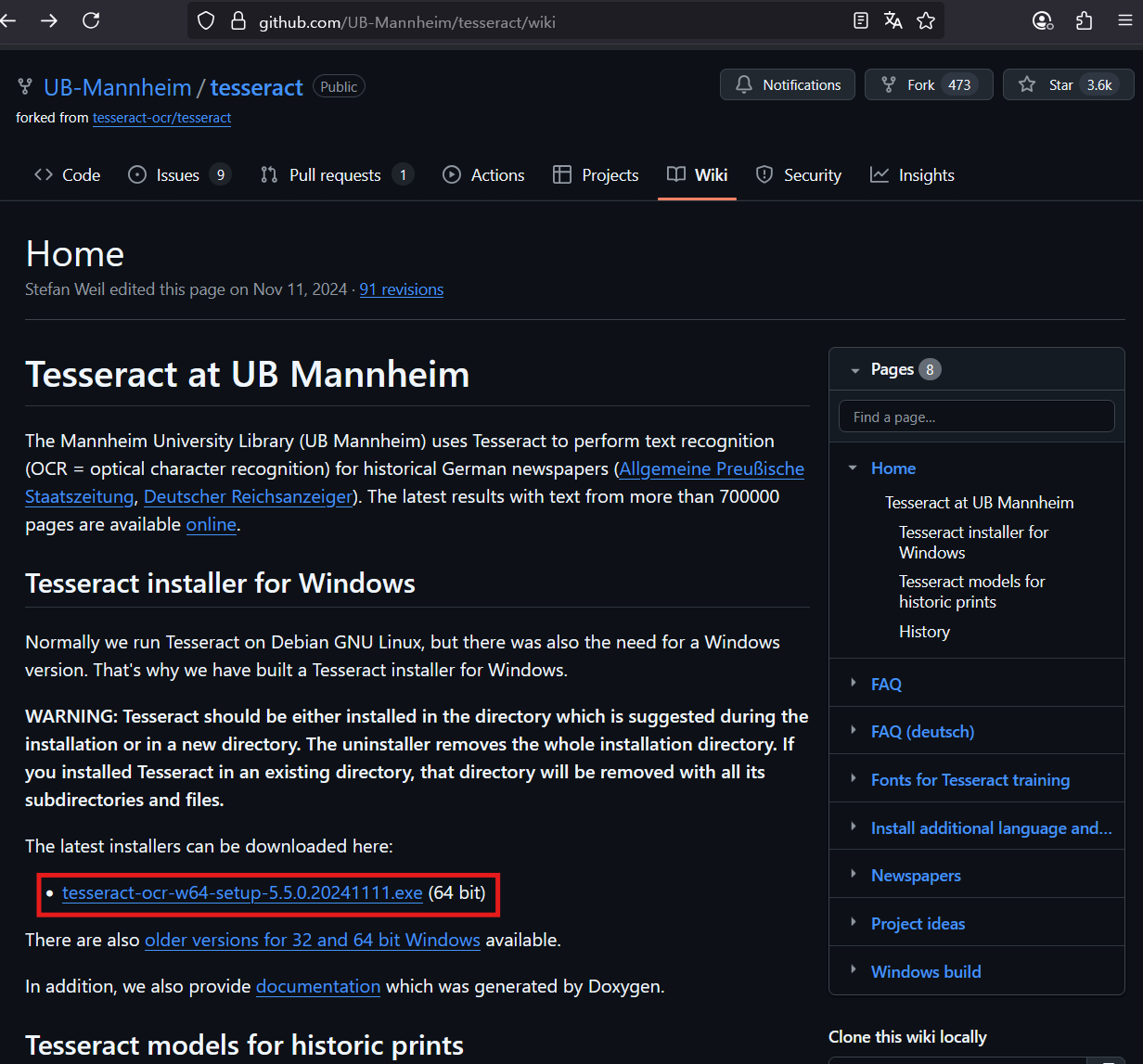




※ 설치: script data - Hangul script / Hangul vertical script, language data - Korean (한글 인식이 필요합니다!!)




2) 이미지 처리
OCR 인식률을 높이기 위해서 그래도 글자 구분이 잘 될수 있도록 이미지 처리를 해두면 좋을 것입니다.
일반적으로 OCR을 위한 이미지 처리는 다음의 과정을 거치면 됩니다.
Grayscale → (Blur) → Adaptive Thresholding → Sharpening → Morphological Transformation
각각의 이미지 처리를 위해 opencv를 활용하면 됩니다.
※ 이미지 왜곡이 있을 수 있으므로, 기울기나 왜곡의 보정을 추가할 수 있습니다.
또한 이미지 확대도 필요할 수 있습니다만, Blur의 경우에는 OCR 인식률을 떨어뜨릴 가능성도 있습니다.
3) OCR 및 보정
OCR은 pytesseract, EasyOCR, paddleOCR, Naver CLOVA OCR 등을 활용하면 됩니다.
OCR 패키지를 활용한 결과는 text 자료가 추출됩니다. 이를 필요에 맞춰 보정을 하면 됩니다.
특수문자의 제거나 숫자가 필요하다면 re 패키지의 정규식을 이용하는 등의 방법이 있습니다.
(또한.. 필요하다면 여러 패키지나 모델을 이용한 앙상블도 한 방법이 될 수 있습니다)
'프로젝트' 카테고리의 다른 글
| [프로젝트#2025-1]RAG w/ local LLM (0) | 2025.07.03 |
|---|---|
| [프로젝트#2024-3]초중고교 정보 - 학교 알리미 등 (0) | 2024.06.28 |
